Humans naturally build mental models of object interactions and dynamics, allowing them to imagine how their surroundings will change if they take a certain action. While generative models today have shown impressive results on generating/editing images unconditionally or conditioned on text, current methods do not provide the ability to perform object manipulation conditioned on actions, an important tool for world modeling and action planning.
We propose to learn an action-conditional generative models by learning from unlabeled videos of human hands interacting with objects. The vast quantity of such data on the internet allows for efficient scaling which can enable high-performing action-conditional models. Given an image, and the shape/location of a desired hand interaction, CosHand, synthesizes an image of a future after the interaction has occurred. Experiments show that the resulting model can predict the effects of hand-object interactions well, with strong generalization particularly to translation, stretching, and squeezing interactions of unseen objects in unseen environments. Further, CosHand can be sampled many times to predict multiple possible effects, modeling the uncertainty of forces in the interaction/environment. Finally, method generalizes to different embodiments, including non-human hands, i.e. robot hands, suggesting that generative video models can be powerful models for robotics.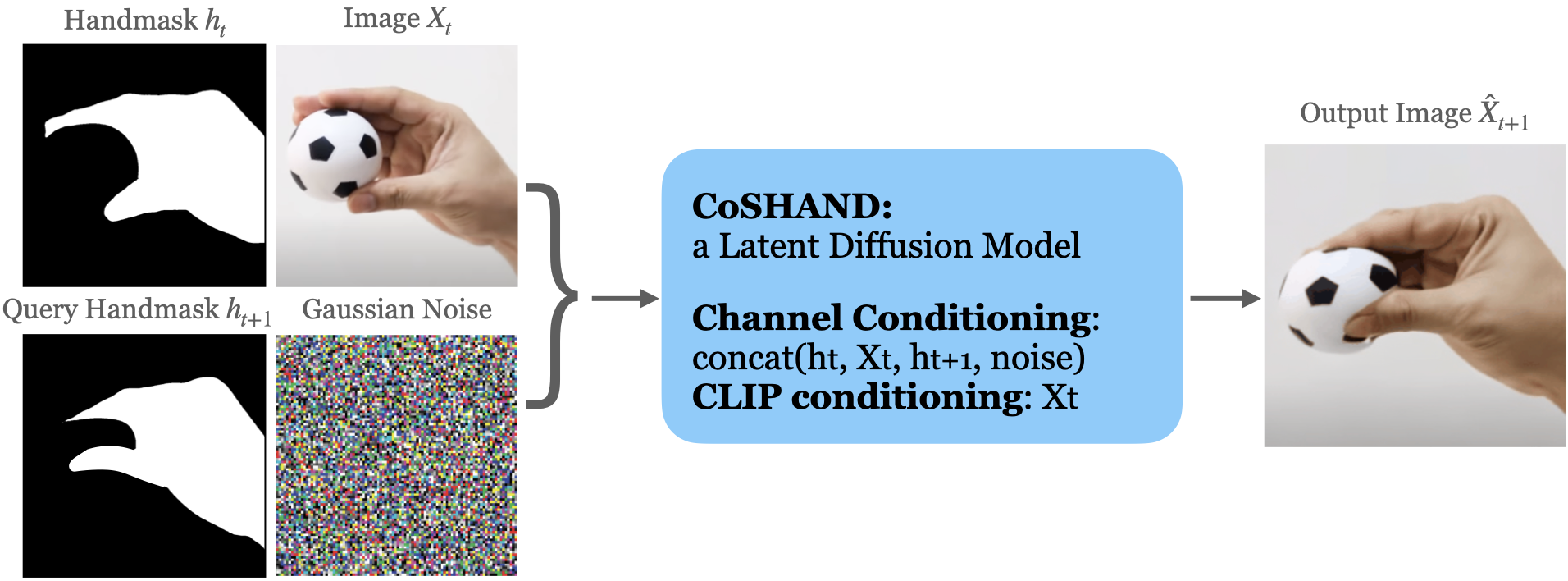




@misc{sudhakar2024controllingworldsleighthand,
title={Controlling the World by Sleight of Hand},
author={Sruthi Sudhakar and Ruoshi Liu and Basile Van Hoorick and Carl Vondrick and Richard Zemel},
year={2024},
eprint={2408.07147},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2408.07147},
}
